
Sette di noi hanno partecipato a un’attività di formazione per iniziare a muovere i primi passi con il Machine learning. Ciascuno ha condotto il proprio studio in autonomia, conciliandolo con la normale attività lavorativa. Nonostante fosse apparsa sin da subito un’attività sfidante, la motivazione e l’estremo interesse che l’argomento ha suscitato in noi ci hanno permesso di arrivare in fondo.
Il percorso davanti a noi
Consapevoli della complessità e della vastità del tema, abbiamo iniziato la nostra attività esplorativa a piccoli passi. Questo viaggio ci ha offerto parecchi spunti di conversazione e ci ha portati a:
- entrare in contatto con i termini e le pratiche;
- conoscere i vari tipi di modello e i problemi che sono in grado di risolvere;
- fare esercizi per acquisire dimestichezza con i framework di Machine learning.
Con l’esperienza pratica, ci siamo resi conto di non avere più così timore della materia. Già con queste prime competenze, siamo ora in grado di riconoscere le situazioni in cui il machine learning può aiutare i nostri clienti a realizzare più velocemente i loro obiettivi.
Come iniziare
Un buon punto di partenza è stato il Machine Learning Crash Course di Google che ci ha permesso di acquisire rapidamente le nozioni di base. Nonostante ci abbia data una buona visione d’insieme, ci siamo subito resi conto che avrebbe soltanto scalfito la superficie.
Studiando i vari algoritmi abbiamo scoperto un mondo interessante ma anche complicato, che affonda le sue radici nella statistica e nel calcolo.
Abbiamo così avuto un’ottima opportunità per approfondire temi contigui alla nostra normale attività lavorativa quotidiana.
Per semplice curiosità (ma anche per non arrenderci subito difronte alla sfida), abbiamo integrato il corso con ottimi articoli tecnici forniti da alcuni siti web specializzati, che si sono rivelati valide risorse per chiunque decida di cimentarsi con il machine learning:
- kdnuggets.com contiene svariati corsi gratuiti, dalla trasformazione dei dati alle applicazioni pratiche;
- towardsdatascience.com ha una vasta raccolta di articoli tecnici sul tema Data Science;
- kaggle.com e huggingface.co sono community i cui membri condividono modelli, dataset ed esempi di codice.
Esercitarsi col machine learning
Portare lo studio a basso livello non è realmente necessario, infatti vengono in nostro soccorso alcuni framework come ML.NET (su .NET), scikit (su Python), Axon (su Elixir) e TensorFlow (su vari ambienti). Essi espongono un’interfaccia di programmazione di alto livello che ci permette di creare dai più semplici modelli di regressione lineare alle più complesse reti neurali, delegando i calcoli matematici al motore computazionale sottostante.
Anche tali framework richiedono formazione, s’intende, ma la curva di apprendimento si addolcisce molto grazie ai numerosi tutorial trovati online o nei libri. Nel nostro caso sono state particolarmente utili le guide passo-passo di Microsoft su ML.NET e il libro Machine Learning in Elixir di Sean Moriarity.

Strada facendo, abbiamo raccolto i nostri appunti ed esercizi pratici in questo repository Github:
https://github.com/Moreno-Gentili/side-project-ml
Procurarsi un dataset
Ad oggi, molte attività umane sono tracciate e misurate da applicazioni. Dall’ambito medico a quello dell’intrattenimento, viene raccolta una enorme mole di dati che nasconde una conoscenza che possiamo portare a galla, ovviamente con il consenso delle persone coinvolte e nel rispetto della loro privacy.
Per il nostro primo esercizio, abbiamo scelto di lavorare con un dataset pubblico (e datato) come il California housing prices che contiene vari esempi di immobili californiani e le loro caratteristiche oggettive, più propriamente definite feature.
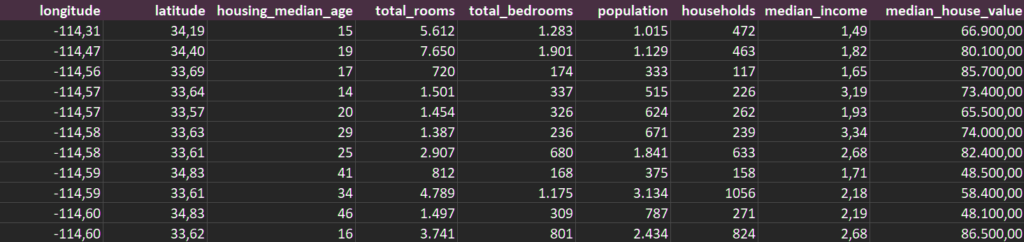
Il dataset contiene inoltre i prezzi di vendita di ciascun immobile, cioè le cosiddette label. Il nostro obiettivo è quello di addestrare un modello che impari quale correlazione esiste tra le feature e la label, e riesca quindi a predire i prezzi di vendita di immobili non inclusi nel dataset.
I modelli di machine learning sono così utili perché possono fare previsioni e supportare le persone nel loro processo decisionale.
Nel caso specifico, siamo di fronte a un problema di regressione lineare, così detto perché ci permette di ottenere previsioni di valori continui, come lo è il prezzo di vendita di un immobile.
Data visualization
Una delle prime e principali attività di un data scientist consiste nel visualizzare il contenuto di un dataset per identificare i casi limite e rilevare eventuali errori. Un modello di machine learning, infatti, sarà tanto più affidabile nelle sue previsioni quanto più la correlazione tra feature e label è ben identificabile.
Dati erronei o incompleti possono ridurre l’affidabilità del modello e perciò è importante che vengano identificati e corretti.
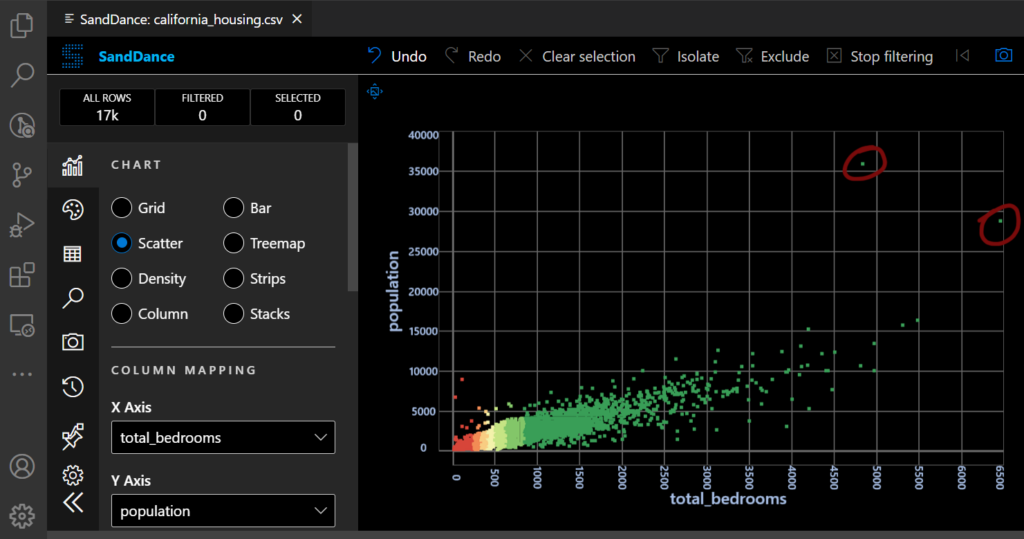
Per questo che abbiamo installato l’estensione SandDance di Microsoft DevLabs per VSCode: grazie ad essa siamo stati in grado di aggregare i dati e visualizzarli su vari tipi di grafico. Così abbiamo potuto identificare gli outlier, ovvero gli esempi molto distanti dal caso normale o frutto di errori nei dati.
Inoltre, usando i Polyglot Notebook di .NET e i pacchetti MathNet.Numerics e Plotly, siamo stati in grado di generare la correlation matrix, ovvero un grafico che mostra l’intensità con cui ciascuna feature è correlata alla label.
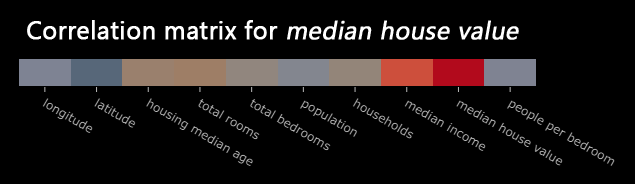
Questa attività è molto utile a identificare le feature più rilevanti, che dovremo poi selezionare per l’apprendimento del modello. Includere anche le feature irrilevanti, infatti, sarebbe controproducente.
Feature engineering
Anche se alcune feature non mostrano una correlazione evidente con la label, non vuol dire che siano inutili a prescindere. Il data scientist ha il compito di raffinare il dataset originale in modo da migliorare l’affidabilità del modello.
Con la sua esperienza (e con esperimenti) un data scientist è in grado di capire come raffinare le feature grezze in modo da renderle rilevanti.
Con la pratica del feature cross, è possibile incrociare due o più feature all’apparenza poco rilevanti. Ad esempio, la latitudine e la longitudine, se prese singolarmente, non sono molto indicative. Se invece le si usa per ottenere una nuova feature che indichi la precisa zona geografica di appartenenza, allora si riveleranno molto più utili perché la zona è certamente un dato influente nel determinare il prezzo di vendita di un immobile.
Inoltre, le feature come latitudine e longitudine hanno una risoluzione fin troppo elevata, che di fatto non aiuta il modello a fare previsioni più precise. In questo caso, discretizzarle aiuta.
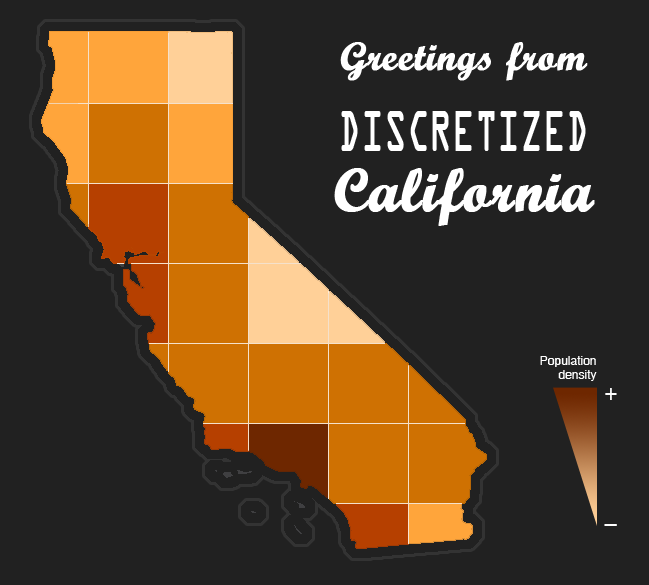
Discretizzare una feature vuol dire dividere i valori continui in un insieme di valori finito. Partendo da coordinate numeriche, le trasformeremo in modo da ottenere aree abitative omogenee, cioè i perimetri geografici all’interno dei quale gli esempi del dataset hanno tutti una stessa label comparabile, a parità di altre feature.
Embeddings
Non tutti i valori contenuti in un dataset possono essere usati tali e quali per l’apprendimento di un modello. Le immagini, l’audio o i valori testuali devono prima essere trasformati. Ad esempio, affinché il nome di una città sia usabile con un modello di Machine learning, è necessario ottenere il suo embedding, ovvero una rappresentazione numerica di quel nome.
Una delle tecniche per ottenere gli embeddings è chiamata one-hot encoding ed è utile soprattutto con valori testuali discreti. Se il nostro dataset contenesse immobili di tre città californiane, potremmo rappresentare tali città come un vettore sparso di tre elementi, proprio perché tre sono le città comprese nel dataset. Solo uno dei tre valori sarebbe un “1”, cioè quello a cui l’immobile appartiene, mentre gli altri sarebbero “0”. Questo vettore diventa quindi a tutti gli effetti una feature dell’immobile.

Avendo ora un valore numerico distinto a rappresentare ogni città, il modello è in grado di imparare come contribuisce ciascuna di esse a determinare il prezzo di vendita di una casa.
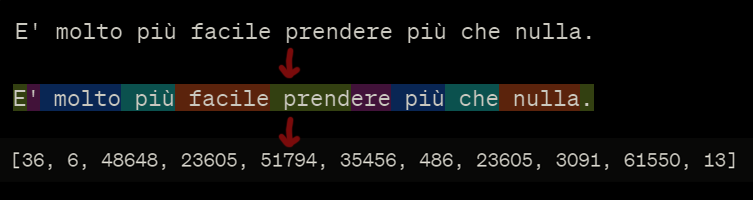
Un procedimento simile, definito tokenizzazione, viene usato anche dai modelli linguistici come GPT-4 di OpenAI. Anche in questo caso, infatti, il testo viene rappresentato come un vettore di interi. In questo caso si tratta di un vettore denso perché i numeri al suo interno rappresentano gli ordinali di ciascuna parola o simbolo di punteggiatura all’interno di un dizionario. Questo processo è chiamato tokenizzazione.
Addestrare un modello
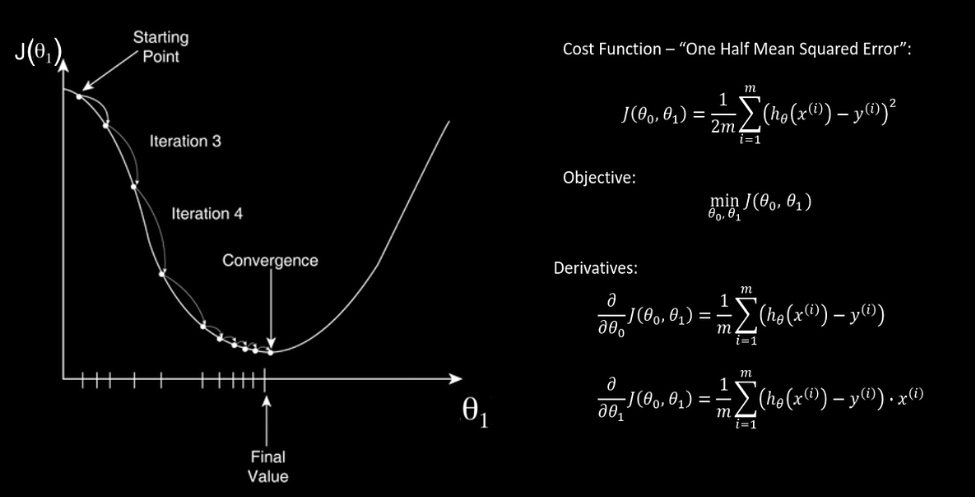
Ora che il dataset è pronto, possiamo usarlo per addestrare un modello. Curiosamente, abbiamo scoperto che alcuni degli algoritmi usati in questa fase non sono affatto una novità recente. Ad esempio, il gradient descent, che è l’algoritmo che migliora l’affidabilità di un modello per iterazioni successive, è stato proposto per la prima volta nel 1847 dal matematico francese Cauchy. È solo grazie alle innovazioni tecnologiche recenti che si sono potuti superare i primi inverni delle intelligenze artificiali, ovvero periodi storici in cui la carenza di investimenti o di mezzi non permisero di realizzare prontamente le promesse delle IA.
Il gradient descent è un algoritmo che opera sul modello: iterativamente, lo usa per ottenere delle previsioni, misurarne gli errori e aggiustare il tiro fino a convergere, cioè fino ad arrivare a una performance quasi ottimale, oltre la quale non si avrebbero miglioramenti tangibili.
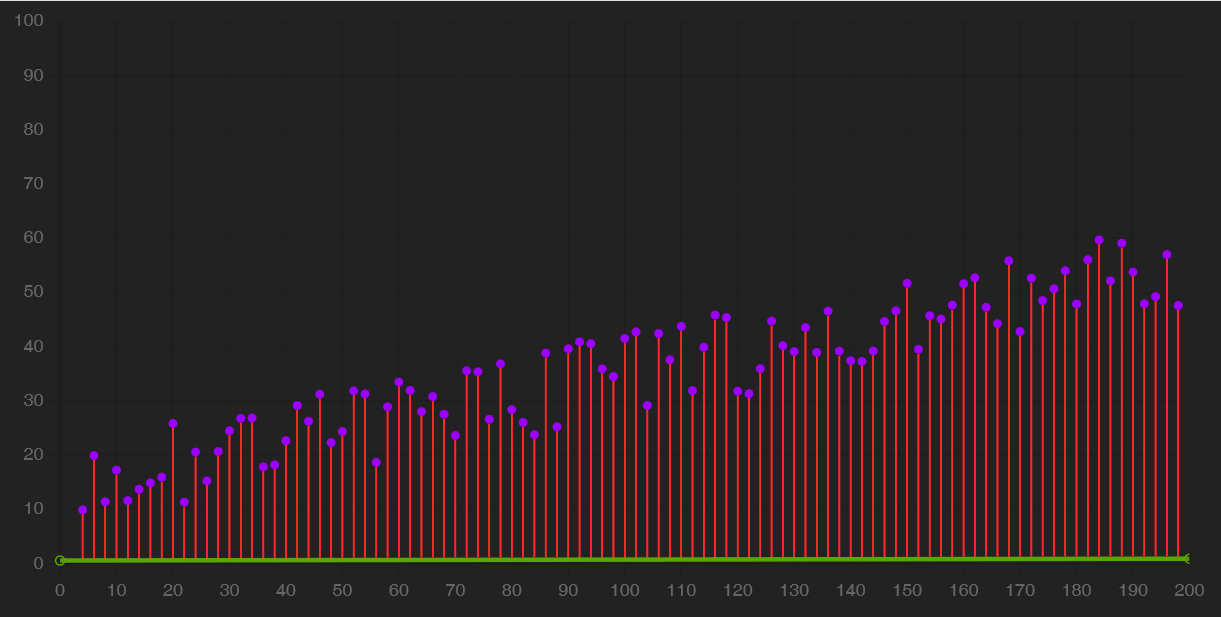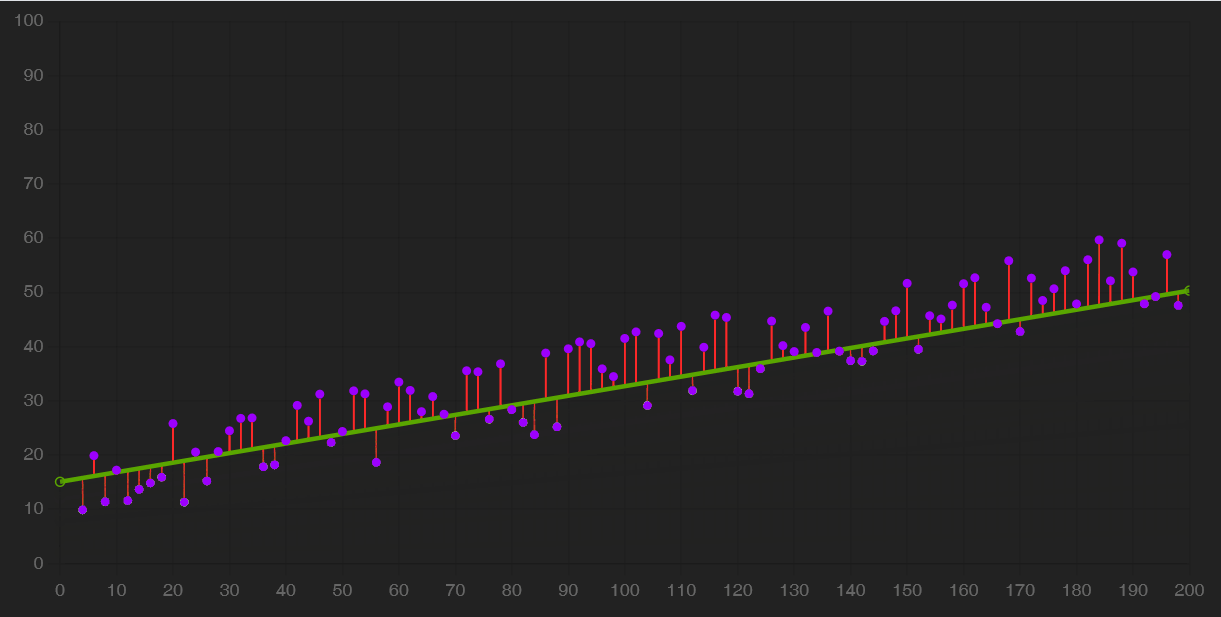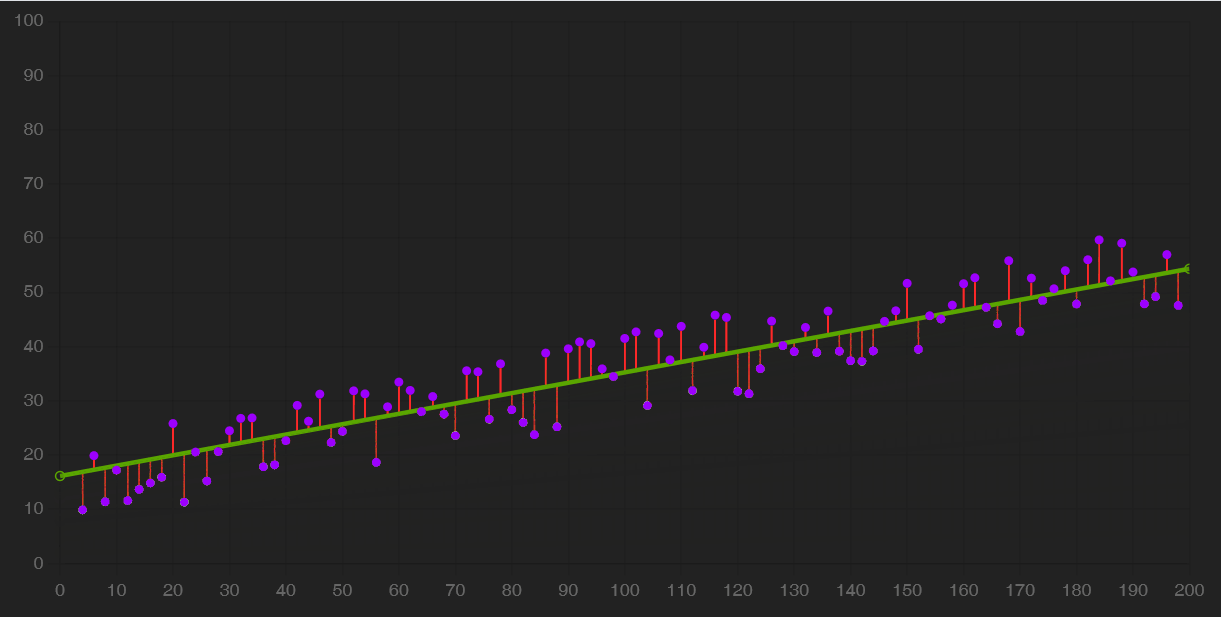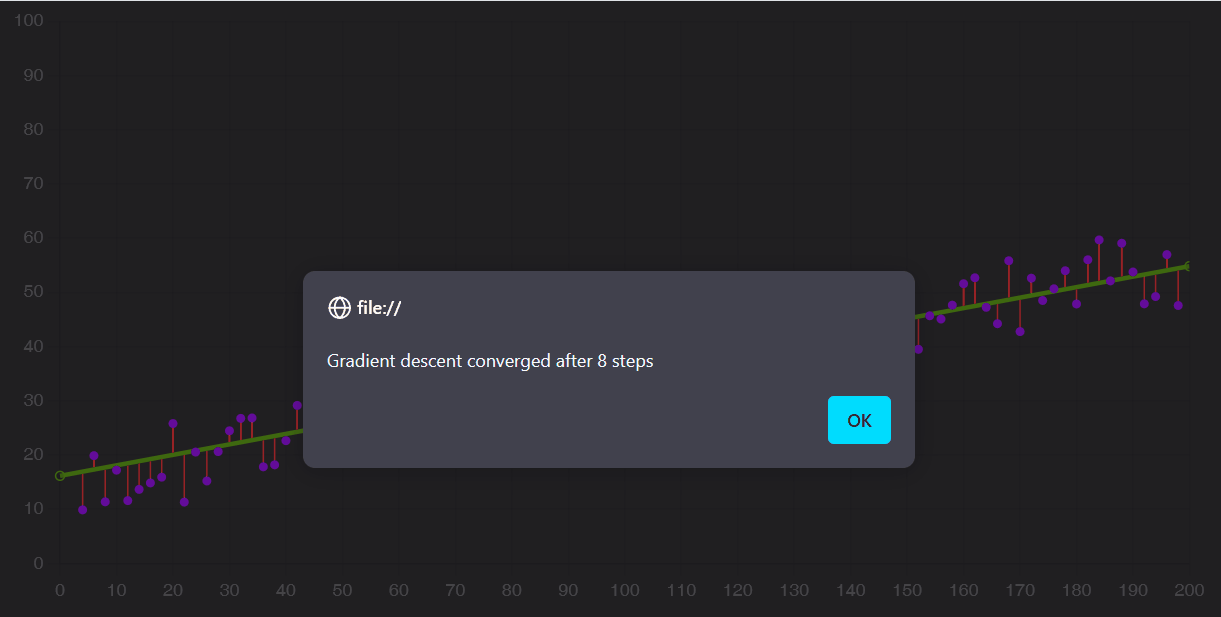
In alcuni casi, come quello della regressione lineare, il modello è una semplice retta. Il gradient descent ne modifica la pendenza (slope) e l’intersezione con l’asse Y (bias) affinché approssimi i dati meglio che può.
Un data scientist deve anche saper scegliere gli iperparametri come il learning rate, cioè la velocità con cui ci si avvicina all’ottimo, e la dimensione del batch cioè il sottoinsieme di esempi da includere nell’apprendimento. Includere l’intero dataset, o comunque scegliere gli iperparametri in maniera poco oculata, può comportare un costo eccessivo in termini sia di tempo che di denaro.
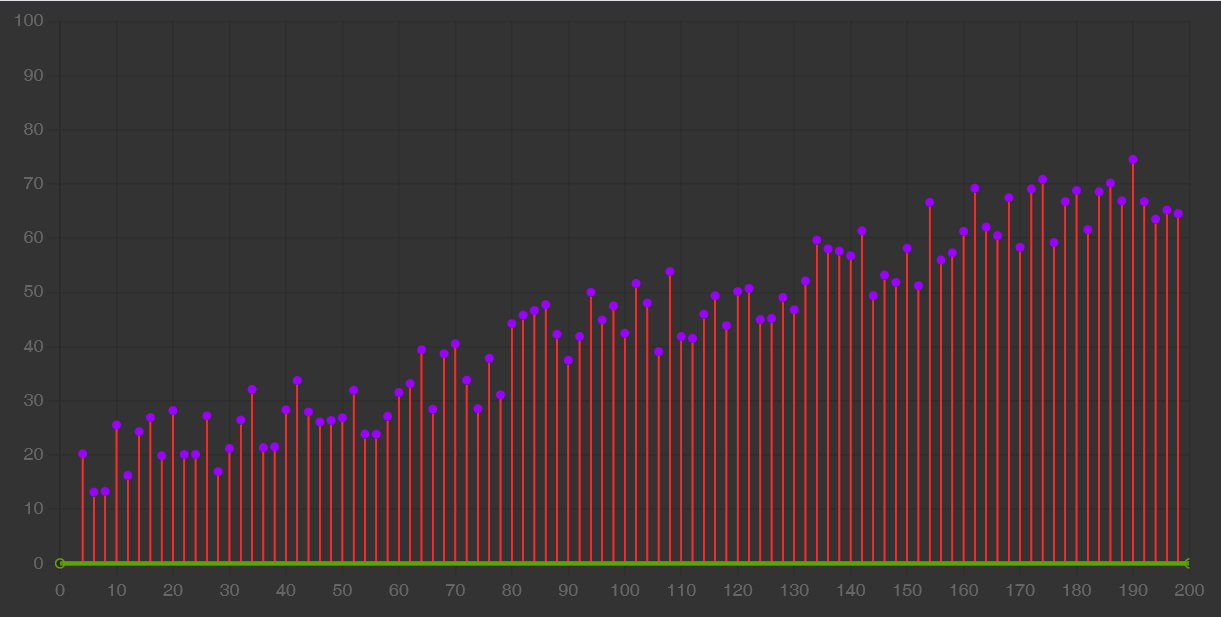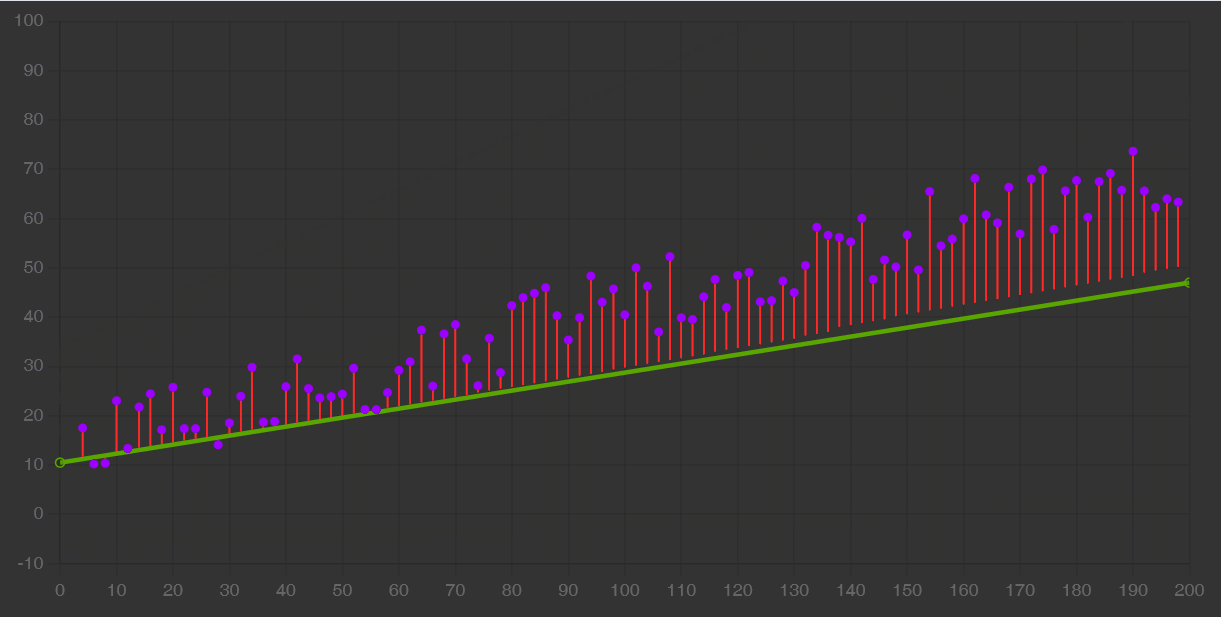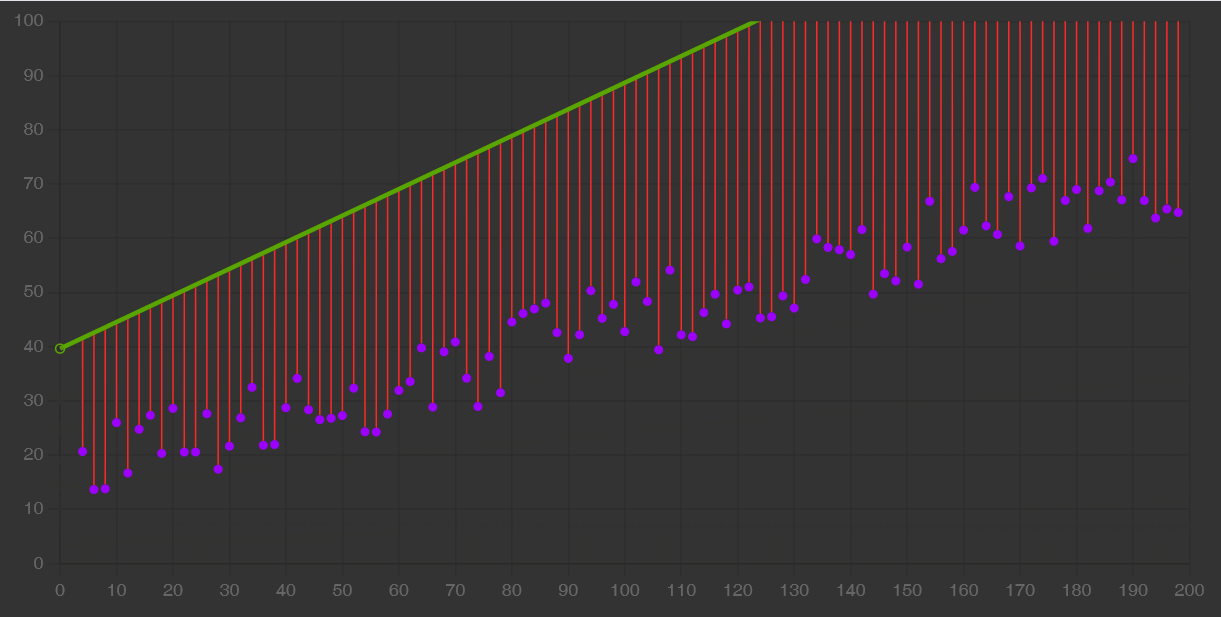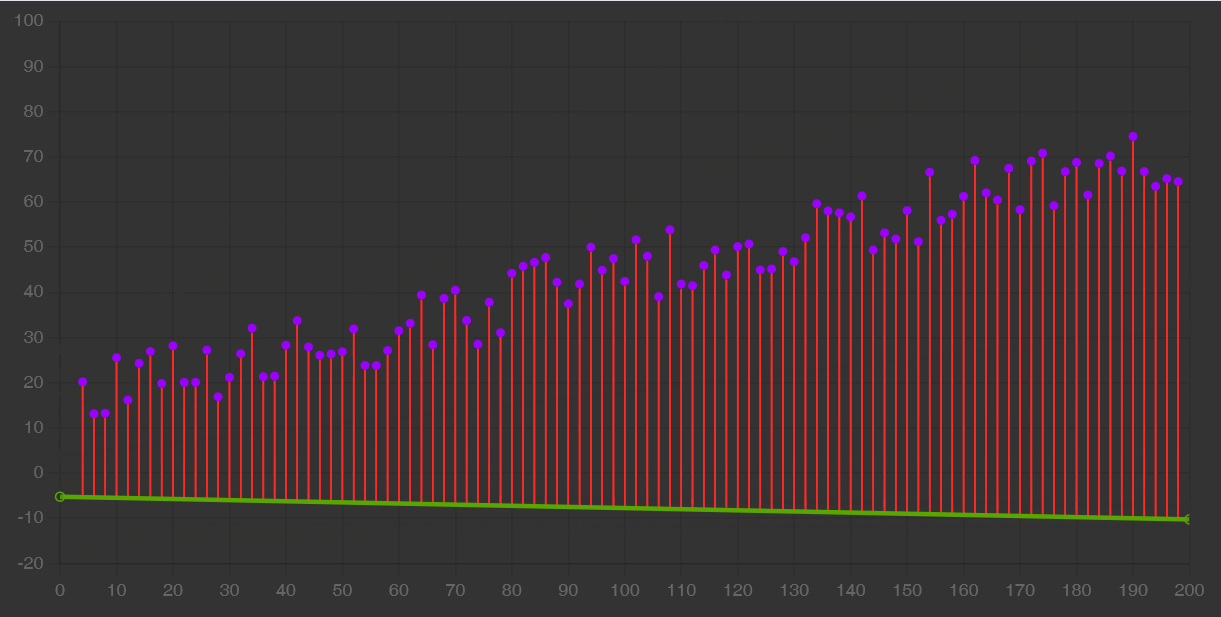
Perciò abbiamo imparato che è importante compiere degli esperimenti controllati e avere un feedback precoce su quali siano le scelte che funzionano meglio. Non ci sono iperparametri universalmente validi.
Verificare l’affidabilità di un modello
Al termine dell’apprendimento va fatta una valutazione dell’affidabilità del modello. Solo in base a questo riusciremo a determinare se sarà effettivamente utile al raggiungimento dell’obiettivo.
I modelli forniscono previsioni, perciò è molto importante
stimare il rischio di previsioni errate.
Che rischio comporta mancare una vendita perché il prezzo è stato valutato troppo alto? E quanto maggiore è invece il rischio se l’immobile viene venduto a un prezzo troppo basso? Analizzare casi come questi ci aiuterà a fare un uso consapevole dei modelli di machine learning.
Metriche come la R-Squared, detto anche coefficiente di determinazione, ci servono ad avere un giudizio sintetico dell’affidabilità del modello.
Nei problemi di classificazione, i diagrammi come la confusion matrix mostrano quante delle previsioni fatte dal modello siano esatte e quante no.

I prossimi passi
Le nostre sessioni di formazione hanno toccato per lo più problemi di supervised learning, come linear regression e classification. Nel futuro esploreremo anche il tema delle reti neurali e del deep learning. Nel mentre, abbiamo già iniziato ad usare strumenti di IA generativa e modelli linguistici come GPT-4, sia con OpenAI che con Microsoft Azure.
Il veloce avanzamento di queste tecnologie ci rende ancor più desiderosi di apprenderle 🙂

